
MySQL Server Architecture.
from the top, we have services for clients to connect to MySQL, services like connection handling, authentication and security,
What is inside the box is the brain of MySQL, here we have query parsing, analysis, optimization, caching all the built-in functions (e.g., dates, times, math, and encryption) stored procedures, triggers, and views
The third layer contains the storage engines. They are responsible for storing and retrieving all data stored “in” MySQL (we have different engines like MyISAM, InnoDB). The storage engines don’t parse SQL or communicate with each other; they simply respond to requests from the second layer.
Connection Management
1- Each client connection gets its own thread within the server process.
2- The connection’s queries execute within that single thread, which in turn resides on one core or CPU.
3- The server caches threads, so they don’t need to be created and destroyed for each new connection
Optimization and Execution
1- MySQL parses queries to create an internal structure (the parse tree), and then applies a variety of optimizations. These can include rewriting the query, determining the order in which it will read tables, choosing which indexes to use, and so on.
2- You can pass hints to the optimizer through special keywords in the query, affecting its decision making process.
3-You can also ask the server to explain various aspects of optimization. This lets you know what decisions the server is making and gives you a reference point for reworking queries, schemas, and settings to make everything run as efficiently as possible.
4- Before parsing the query, the server consults the query cache, which can store only SELECT statements, along with their result sets. If anyone issues a query that’s identical to one already in the cache, the server doesn’t need to parse, optimize, or execute the query at all—it can simply pass back the stored result set.
Concurrency Control
1- Concurrency is controlled by locks, These locks are usually known as shared locks and exclusive
locks, or read locks and write locks.
2- Read locks on a resource are shared, or mutually nonblocking: many clients can read from a resource at the same time and not interfere with each other.
3- Write locks, on the other hand, are exclusive—i.e., they block both read locks and other write
locks
4- locks consume resources.
5- In mySQL we have Table locks and Row locks
Isolation Level
READ_UNCOMMITTED: a transaction may read data that is still uncommitted by other transactions which may lead to dirty reads.
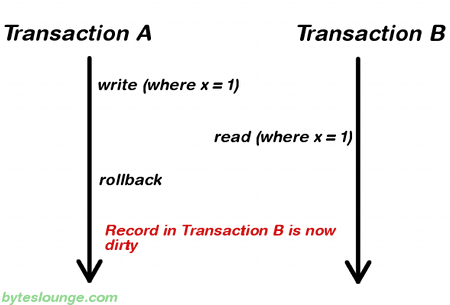
READ_COMMITTED: a transaction can't read data that is not yet committed by other transactions. This fixes dirty read, but may lead to nonrepeatable read. (read different value in the course of a transaction).
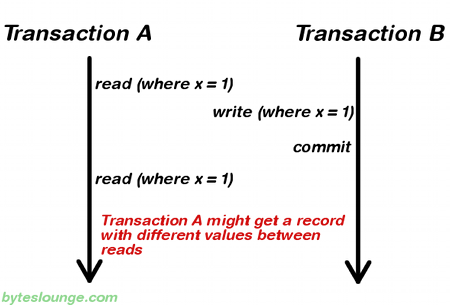
REPEATABLE_READ: if a transaction reads one record from the database multiple times the result of all those reading operations must always be the same. This eliminates both the dirty read and the non-repeatable read issues, however it creates a Phantom Read issue (a transaction fetched a range of records multiple times from the database and obtained different result sets).

SERIALIZABLE: the most restrictive of all isolation levels. Transactions are executed with locking at all levels (read, range and write locking) so they appear as if they were executed in a serialized way.

Deadlock
Transaction #1
START TRANSACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2002-05-01';
UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = '2002-05-02';
COMMIT;
Transaction #2
START TRANSACTION;
UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = '2002-05-02';
UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = '2002-05-01';
COMMIT;
If each transaction executes its first query and update a row of data, locking it in the process. Each transaction will then attempt to update its second row, only to find that it is already locked. The two transactions will wait forever for each other to complete, unless something intervenes to break the deadlock.
handling DeadLock is differ between storage engines.
1- InnoDB storage engine, will notice circular dependencies and return an error instantly, Others will give up after the query exceeds a lock wait timeout,
Transaction Logging
1- Instead of updating the tables on disk each time a change occurs, the storage engine can change its in-memory copy of the data. This is very fast.
2- The storage engine can then write a record of the change to the transaction log, which is on disk and therefore durable. This is also a relatively fast operation, because appending log events involves sequential I/O in one small area of the disk instead of random I/O in many places.
3- Then, at some later time, a process can update the table on disk.
4- this is called (write-ahead logging) which actually ends up writing the changes to disk twice.
5- If there’s a crash after the update is written to the transaction log but before the changes are made to the data itself, the storage engine can still recover the changes upon restart.
Transactions in MySQL
1- MySQL provides two transactional storage engines: InnoDB and NDB Cluster. Several third-party engines are also available; the best-known engines right now are XtraDB and PBXT
2- MySQL operates in AUTOCOMMIT mode by default, which means it automatically executes each query in a separate transaction
Multiversion Concurrency Control
1- Most of MySQL’s transactional storage engines don’t use a simple row-locking mechanism. Instead, they use row-level locking in conjunction with a technique for increasing concurrency known as multiversion concurrency control (MVCC)
2- MVCC has less overhead
3- MVCC has 2 types optimistic and pessimistic
4- Optimistic Locking: when you read a record, take note of a version number) and check that the version hasn't changed before you write the record back.
5- Pessimistic Locking: is when you lock the record for your exclusive use until you have finished with it.
6- In Hibernate, Optimistic Locking is obtained by using @Version.
7- MVCC works only with the REPEATABLE READ and READ COMMITTED isolation levels
MySQL’s Storage Engines
1- InnoDB is transactional storage engine
2- MyISAM is not transactional
3- MyISAM provides more types of indexes like spatial (GIS)
4- Never go with MyISAM
5- XtraDB is another storage engine for high transaction systems
No comments:
Post a Comment